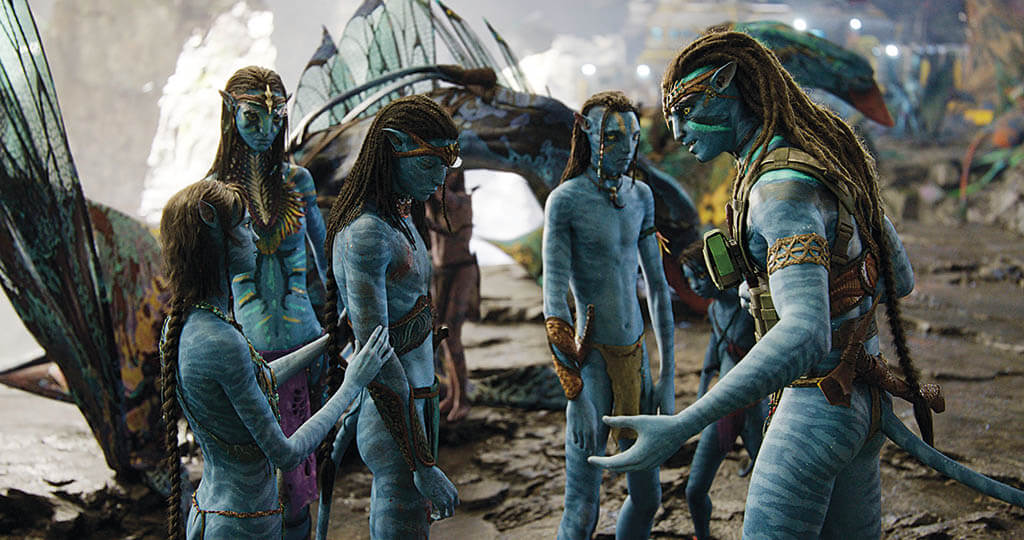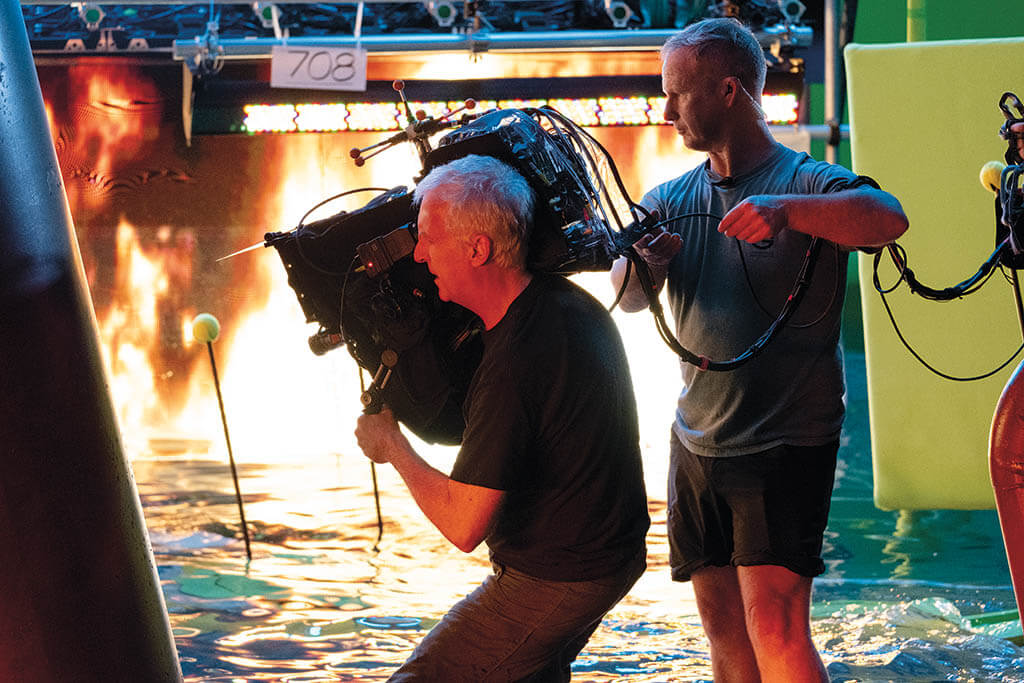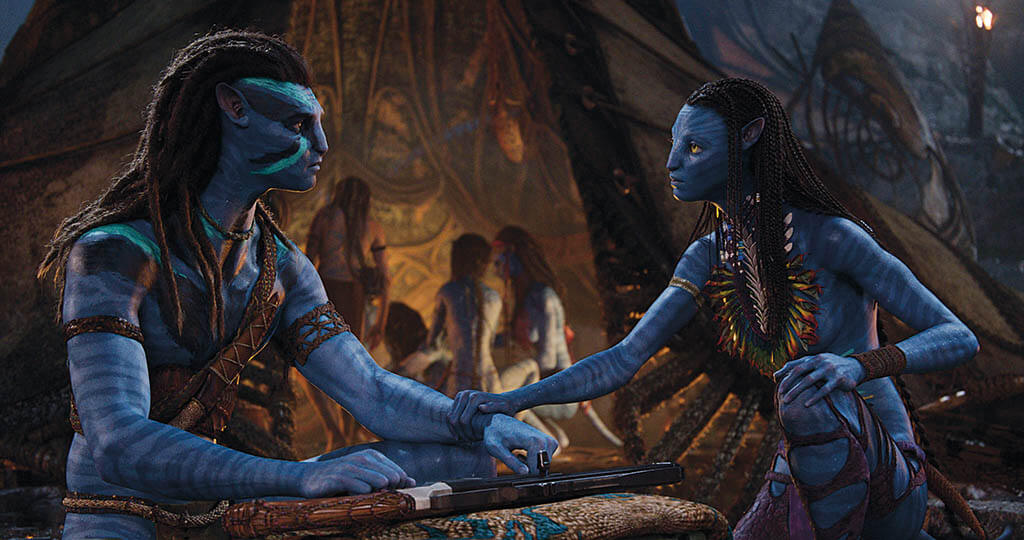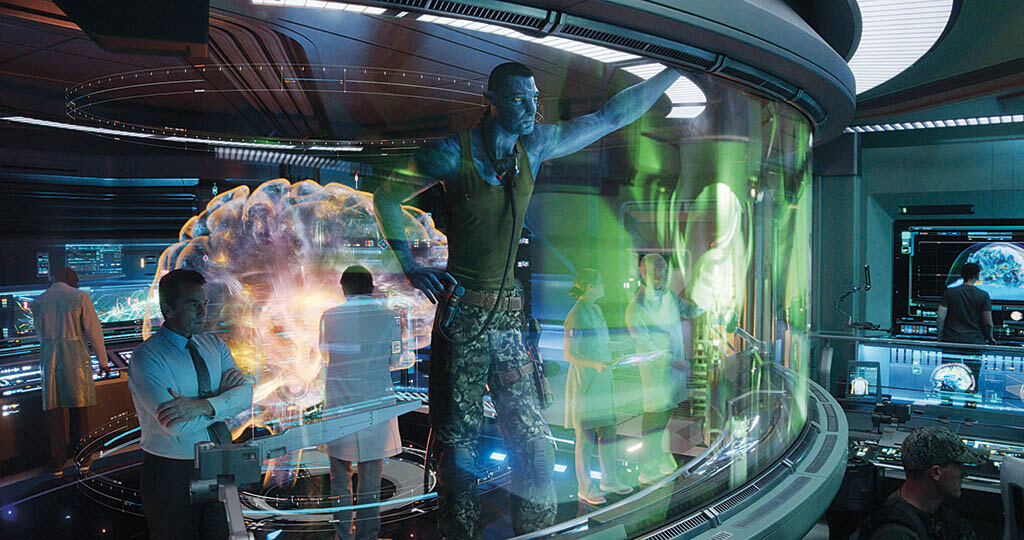By TREVOR HOGG

Images courtesy of 20th Century Studios
After recreating a famous nautical disaster that became the highest-grossing film of all time, filmmaker James Cameron turned his focus towards the skies and imagined what galactic colonialism would look like if humans discovered other inhabitable planets and moons. Avatar went on to unseat Titanic at the box office and is now being expanded into a franchise consisting of four planned sequels, the first of which, Avatar: The Way of Water, takes places 14 years after the original movie, where wheelchair-bound mercenary Jake Sully (Sam Worthington) leaves behind his crippled body for a genetically engineered human/Na’vi hybrid body to live with the indigenous Neytiri (Zoe Saldana) on the lunar setting of Pandora.
“Visual effects allow us to put up on the screen compelling and emotive characters that could not be created with makeup and prosthetics, and cannot be as engaging with robotics, and it allows us to present a world that doesn’t exist in a photoreal way as if that world really exists,” Producer Jon Landau remarks. “Those two things, combined with the story that we have, creates a compelling cinematic experience.”
The biggest technical advancement has been in facial capture. “On the first movie, we recorded facial performance with a single standard-definition head rig,” Landau details. “This time around we’re using two high-definition head rigs. We’re capturing quadruple, or more, the type of data to drive the performance. Wētā FX has a smart learning algorithm that trains on what the actors do after we put them into FACS session.”
A template is constructed before principal photography commences. “We probably have 160 people here in Los Angeles that build these files, that are a slightly cruder representation of the movie but describe exactly what it is we want to achieve,” Production Visual Effects Supervisor Richard Baneham explains. “We acquire our performances, go through an editorial process selecting the preferred performances, and put them into what we call camera loads, which are moments in time as if they are happening. A scene might be made up of 10 ‘camera loads,’ or just one depending on the consistency of the performances that we need to deal with and the intended cutting pattern. It is a true representation of our intended lighting, environments and effects to the point when we’re done with it, Jim often asks, ‘Does it match the template?’”