

If there’s a buzz phrase right now in visual effects, it’s “machine learning.” In fact, there are three: machine learning, deep learning and artificial intelligence (A.I.). Each phrase tends to be used interchangeably to mean the new wave of smart software solutions in VFX, computer graphics and animation that lean on A.I. techniques.
Already, research in machine and deep learning has helped introduce both automation and more physically-based results in computer graphics, mostly in areas such as camera tracking, simulations, rendering, motion capture, character animation, image processing, rotoscoping and compositing.
VFX Voice asked several key players – from studios to software companies and researchers – about the areas of the industry that will likely be impacted by this new world of A.I.

What exactly is machine or deep learning? An authority on the subject is Hao Li, a researcher and the CEO and co-founder of Pinscreen, which is developing ‘instant’ 3D avatars via mobile applications with the help of machine learning techniques. He describes machine learning (of which deep learning is a subset) as the use of “computational frameworks that are based on artificial neural networks which can be trained to perform highly complex tasks when a lot of training data exists.”
Neural networks have existed for some time, explains Li, but it was only relatively recently that ‘deep’ neural networks (which have multiple layers) can be trained efficiently with GPUs and massive amounts of data. “It turned out that deep learning-based techniques outperformed many, if not most, of the classic computer vision methods for fundamental pattern recognition-related problems, such as object recognition, segmentation and other inference tasks,” says Li.
Since many graphics-related challenges are directly connected to vision-related ones – such as motion capture, performance-driven 3D facial animation, 3D scanning and others – it has become obvious that many existing techniques would immediately benefit from deep learning-based techniques once sufficient training data can be obtained.
“More recently,” adds Li, “researchers have further come up with new forms of deep neural network architectures, where believable images of a real scene can be directly generated, either from some user input or even from random noise. Popular examples for these deep generative models include generative adversarial networks (GAN) and variational autoencoders (VAE).”

More on Pinscreen’s own implementation of these kinds of networks is below, but first a look at one of the most front-and-center examples of where machine learning has been used in VFX in recent times – Digital Domain’s Thanos in Avengers: Infinity War. Here, the visual effects studio used a type of machine learning to transform Josh Brolin’s face – captured with head-cam cameras looking onto facial tracking markers – into the film’s lead character. This involved taking advantage of facial-capture training data.
“We already knew that we could build a system that will take motion-capture data and produce a result,” states Digital Domain’s Head of Digital Humans, Darren Hendler. “With machine learning, we can take the original system we built and now feed in corrections. All future results will then be corrected in the desired manner. This is a more rudimentary version of machine learning, but really shows great promise in speeding up the work and improving the quality.”
Since their work on Infinity War, Digital Domain has furthered its deep learning techniques to create an entirely new facial-capture system. “Now,” says Senior Director of Software R&D, Doug Roble, “we can take a single image and in real time re-create a high-resolution version of any actor to a similar quality as our final result in the film. How this works sometimes seems like pure magic, but like all machine learning, it can be very temperamental and unpredictable, which makes the solution finding particularly rewarding.”
At Pinscreen, one of the goals of the company has been to generate photorealistic and animatable 3D avatars complete with accurate facial and hair detail from single mobile phone images of users. They’ve been relying on deep learning approaches to make that possible, based on extensive ‘semi-supervised’ or ‘unsupervised’ training data. The data, coupled with deep neural networks, is used to help predict the correct results for what a 3D avatar should look like – for example, to work out what facial expression should be displayed.
Pinscreen’s results are sometimes compared to ‘deep fake’ face-swapping videos, which have gained popularity by using deep learning techniques to re-animate a famous person’s face to make them say things they never actually said or appear where they never actually appeared. Li notes that “while the deep fakes code still requires a large amount of training data, i.e. video footage of a person, to create a convincing model for face swapping, we have shown recently at Pinscreen that the paGAN (photorealistic avatar GAN) technology only needs a single input picture.”
Research that Li is part of at the University of Southern California is looking at ways of generating photorealistic and fully-clothed production-level 3D avatars without any human intervention, and how to model general 3D objects using deep models. “In the long term,” he says, “I believe that we will fully democratize the ability to create complex 3D content, and anyone can capture and share their stories immersively, just like we do with video nowadays.”
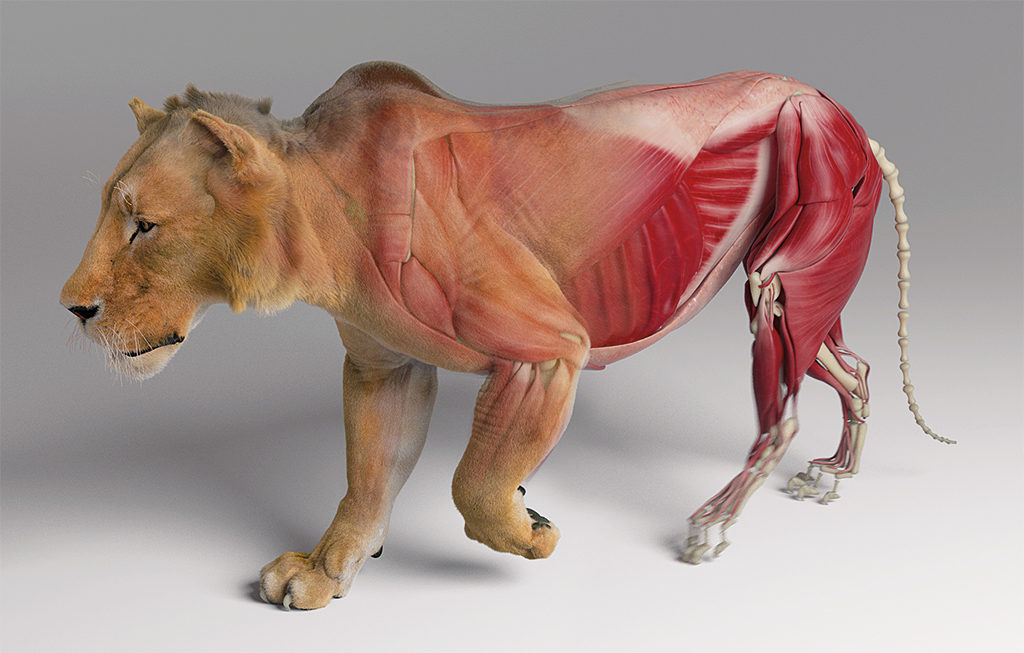
The use of machine and deep learning techniques in the creation of CG creatures and materials is still relatively new, but incredibly promising, which is why several companies have been dipping their toes in the area. Ziva Dynamics, which offers physically-based simulation software called Ziva VFX, has been exploring machine learning, particularly in relation to its real-time solver technology.
“This technology,” explains Ziva Dynamics co-CEO and co-founder James Jacobs, “makes it possible to convert high-quality offline simulations, crafted by technical directors using Ziva VFX, into performant real-time characters. We’ve deployed this tech in a few public demonstrations and engaged in confidential prototyping with several leading companies in different sectors to explore use cases and future product strategies.”
“The machine learning algorithms [enable artists] to interactively pose high-quality Ziva characters in real-time,” adds Jacobs. “The bakes produced from offline simulations are combined with representative animation data through a machine learning training process. From that, our solvers rapidly approximate the natural dynamics of the character for entirely new positions. This results in a fast, interactive character asset that achieves really consistent shapes, all in a relatively small file.”
Allegorithmic, which makes the Substance suite of 3D texturing and material creation tools, has also been exploring the field of A.I. to combine several material-related processes such as image recognition and color extraction, into a single tool, called Project Substance Alchemist.
Project Substance Alchemist’s A.I. capabilities are, in particular, powered by NVIDIA GPUs (NVIDIA itself is at the center of a great deal of computer graphics-related machine learning research). For one side of the Project Substance Alchemist software, the delighter – which was created to help artists remove baked shadows from a base color or reference photo – a neural network was created from Substance’s material library to train the system. Artists need their images to be free of such shadows in order to get absolute control over the material. The A.I.-powered delighter detects the shadows, removes them, and reconstructs what is under the shadows.
In the motion-capture space, a number of companies are employing machine learning techniques to help make the process more efficient. DeepMotion, for instance, uses A.I. in several ways: to re-target and post-process motion-capture data; to simulate soft-body deformation in real time; to achieve 2D and 3D pose estimation; to train physicalized characters to synthesize dynamic motion in a simulation; and to stitch multiple motions together for seamless transitioning and blending.
“These applications of A.I. solve a variety of problems for accelerating VFX processes, enabling truly interactive character creation, and expanding pipelines for animation and simulation data,” says DeepMotion founder Kevin He. “Machine learning has been used for years to create interesting effects in physics-based animation and the media arts, but we’re seeing a new wave of applications as computations become more efficient and novel approaches, like deep reinforcement learning, create more scalable models.”
Meanwhile, RADiCAL is also utilizing A.I. in motion capture and, in particular, challenging the usual hardware-based approach to capture. “Specifically,” notes RADiCAL CEO Gavan Gravesen, “our solution uses input from conventional 2D video cameras to produce 3D animation that requires little to no cleanup, coding, investment or training.”
“To do that,” adds Gravesen, “we’re not relying on hardware-driven detections of tons of small data points that are aggregated into larger data sums that, after some intensive cleaning up, collectively resemble human activity. Rather, we deliver learning-based, software-driven reconstructions of human motion in 3D space.”


“Now we can take a single image and in real time re-create a high-resolution version of any actor to a similar quality as our final result in the film. It sometimes seems like pure magic how this works, but like all machine learning can be very temperamental and unpredictable, which makes the solution finding particularly rewarding.”
—Doug Roble, Senior Director of Software R&D, Digital Domain






One of the promises of deep and machine learning is as an aid to artists with tasks that are presently labor-intensive. One of thosetasks familiar to visual effects artists, of course, is rotoscoping. Kognat, a company started by Rising Sun Pictures pipeline software developer Sam Hodge, has made its Rotobot deep learning rotoscope and compositing tool available for use with NUKE.
Hodge’s adoption of deep learning techniques, and intense ‘training,’ enables Rotobot to isolate all of the pixels that belong to a certain class into a single mask, called segmentation. The effect is the isolation of portions of the image, just like rotoscoping. “Then there is instance segmentation,” adds Hodge, “which can isolate the pixels of a single instance of a class into its own layer. A class could be ‘person,’ so with segmentation you get all of the people on one layer. With instance segmentation you can isolate a single person from a crowd.
“As an effects artist,” continues Hodge, “you might need to put an explosion behind the actors in the foreground – with the tool you can get a rough version done without interrupting the rotoscoping artists’ schedules, they can focus on final quality and the temporary version can use the A.I. mask.”
Other companies are exploring similar A.I. image processing techniques, including Arraiy, which has employed several VFX industry veterans and engineers to work on machine learning and computer vision tools. “We have built software that makes it easy for creators to create custom A.I. learning algorithms to automate the manual processes that are currently required to generate VFX assets,” says Arraiy Chief Operating Officer, Brendan Dowdle.
“For example, we provide a tool in which an artist can train a neural network to create mattes for an entire shot by providing the networks with a few labels on what the artist desires to segment. Once that network is trained for that particular shot, the algorithm can generate mattes for an arbitrary number of frames, and even in real time, while on set, if desired.”
Foundry, makers of NUKE, says it is also investigating deep learning approaches that could be implemented into its software. This includes in the area of rotoscoping, the more mechanical ‘drudge work’ in VFX and in the workflow side of projects. “There are many eye-catching developments in deep learning which center around image processing,” notes Foundry co-founder and chief scientist, Simon Robinson.
“What’s equally interesting is the application of these algorithms to more organizational or workflow-centric tasks. Modern VFX is an extraordinarily complicated management problem, whether of human or computing resources. This is especially true when running multiple overlapping shows. Spotting scheduling patterns and improving efficiency and resource utilization is one of the areas where better algorithms could make a real difference to the industry.”
There isn’t just one thing that A.I. or machine learning or deep learning is bringing to visual effects, it’s many things. Digital Domain’s Darren Hendler summarizes that “machine learning is making big inroads in accelerating all sorts of slow processes in visual effects. We’ll be seeing machine learning muscle systems, hair systems, and more in the coming years. In the future, I really see all these machine learning capabilities as additional tools for VFX artists to refocus their talents on the nuances for even better end results.”



